
来源:正大期货 2024-06-25 17:26
前几日,英伟达市值打破3万亿美元,将苹果公司甩在死后的故事还没来得及回味。英伟达市值登顶全球*的新闻再次登上各大热搜(发稿前,英伟达市值已泛起较大回落)。
作为AI芯片巨头,英伟达近年来可谓风景无限。
已往,我们看到了许多有关英伟达GPU和CUDA护城河的先容。诚然,经由多年的投入,他们已经确立起了难以逾越的优势。但除此以外,英伟达另有许多隐形护城河,其中,互联手艺也是其在AI浪潮中取得乐成历程中不能忽视的一概略害。
日前,黄仁勋在Computex的主题演讲中,再次透露了未来几年GPU和互连手艺的蹊径图;而另一边,八大芯片巨头抱团取暖和,确立UALink推广组意在制订行业尺度,以打破市场*英伟达的壁垒和垄断。
现在大模子时代来临,随着越来越多的加速器被集成到一起,性能消耗和带宽瓶颈逐渐展现,若何高效传输数据成为了AI芯片互联领域亟待攻克的瓶颈。
在此靠山下,行业厂商加速入局,试图抢占GPU互联市场的新高地。
为什么需要GPU互联手艺?
01
耐久以来,冯·诺依曼架构面临的一个焦点挑战是CPU的盘算速率与内存接见速率之间的不匹配,尤其是与存储装备的速率相比更是天壤之别。这就是业界著名的“内存墙”,其不平衡的生长速率对日益增进的高性能盘算形成了极大制约,成为训练大规模AI模子的瓶颈。
与此同时,随着高性能存储手艺的提高,盘算机组件间通讯的带宽再次成为限制性能提升的要害因素。从“Pascal”P100 GPU一代到“Blackwell”B100 GPU一代,八年间GPU的性能提升了1053倍。
在此趋势下,GPU作为AI时代的焦点处置器,单卡GPU算力和显存有限,无法知足训练需求。为顺应算力需求,需要团结大量GPU甚至多台服务器协同事情,漫衍式训练诉求快速提升。
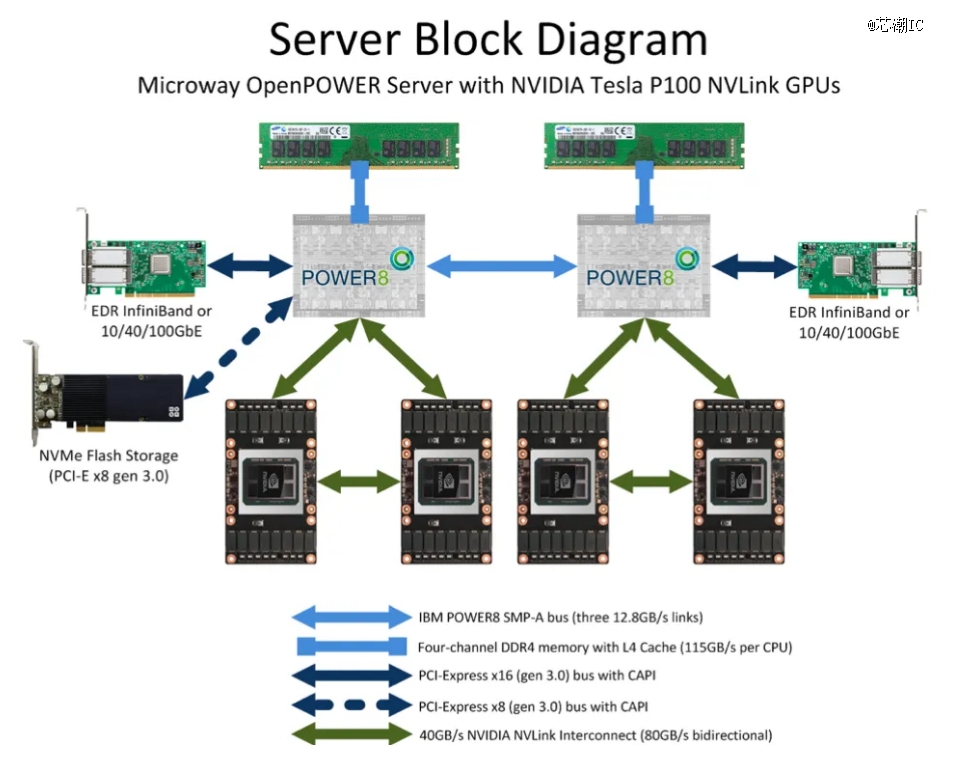
GPU服务结构
在漫衍式系统中,大模子训练对算力基础设施的要求从单卡拓展到了集群层面,这对大规模卡间互联的兼容性、传输效率、时延等指标提出了更高的要求。
自此,GPU互连手艺最先担任主要角色。
GPU互联手艺,百家争鸣
02
众所周知,总线是数据通讯必备管道,是服务器主板上差异硬件相互举行数据通讯的管道,对数据传输速率起到决议性作用。
现在最普及的总线协议为英特尔2001年提出的PCIe(PCI-Express)协议,PCIe主要用于毗邻CPU与其他高速装备如GPU、SSD、网卡、显卡等。2003年PCIe1.0版本宣布,后续大致每过三年会更新一代,现在已经更新到6.0版本,传输速率高达64GT/s,16通道的带宽到达256GB/s,性能和可扩展性不停提高。
AIGC的生长极大刺激算力需求的增添,GPU多卡组合成为趋势。GPU互联的带宽通常需要在数百GB/S以上,PCIe的数据传输速率成为瓶颈,且PCIe链路接口的串并转换会发生较大延时,影响GPU并行盘算的效率和性能。
同时,由于PCIe总线树形拓扑和端到端传输方式限制了毗邻数目和速率,GPU发出的信号需要先转到达PCIe Switch来拓展,PCIe Switch涉及到数据的处置又会造成分外的网络延时,此外PCIe总线与存储器地址星散,每次接见内存会加重网络延迟。
因此,PCIe的传输速率和网络延迟无法知足需求,限制了系统性能。
在市场需求和手艺驱动下,GPUDirect/NVLink/Infinity Fabric/高速以太网/InfiniBand等GPU互联手艺争相推出,“百家争鸣”时代开启。
GPUDirect
在这个历程中,英伟达率先推出了能够提升GPU通讯性能的手艺——GPUDirect,使GPU可以通过PCIe直接接见目的GPU的显存,可实现GPU与其他装备之间直接通讯和数据传输的手艺,大大降低了数据交流的延迟。
传统上,当数据需要在GPU和另一个装备之间传输时,数据必须通过CPU,从而导致潜在的瓶颈并增添延迟。使用GPUDirect,网络适配器和存储驱动器可以直接读写GPU内存,削减不需要的内存消耗,削减CPU开销并降低延迟,从而显著提高性能。GPUDirect手艺包罗GPUDirect Storage、GPUDirect RDMA、GPUDirect P2P和GPUDirect 视频。
但受限于PCIe总线协议以及拓扑结构的一些限制,无法做到更高的带宽。往后,英伟达提出了NVLink总线协议。
NVLink成为主流
已往,我们看到了许多有关英伟达GPU和CUDA护城河的先容。诚然,经由多年的投入,他们已经确立起了难以逾越的优势。但除此以外,英伟达另有许多隐形护城河,NVLink就是其中之一,一个为GPU到GPU互联提供高速毗邻的手艺。
NVLink是一种英伟达提出的高速GPU互联协议,用于毗邻多个GPU之间或毗邻GPU与其他装备(如CPU、内存等)之间的通讯。它允许GPU之间以点对点方式举行通讯,具有比传统的 PCIe 总线更高的带宽和更低的延迟,为多GPU系统提供更高的性能和效率。
对比传统PCIe总线协议,NVLink主要在三个方面做出较大改变:
1)支持网状拓扑目,解决通道有限问题;
2)统一内存,允许GPU共享公共内存池,削减GPU之间复制数据的需要,从而提高效率;
3)直接内存接见,不需要CPU介入,GPU可直接读取相互的内存,从而降低网络延迟。
英伟达官方示意,NVLink是全球首创的高速GPU互连手艺。作为一种总线及其通讯协议,NVLink接纳点对点结构、串列传输,用于毗邻GPU与支持NVLink手艺的CPU,在内存墙无法突破的情形下,*化提升CPU和GPU之间通讯的效率,也可用于多个英伟达GPU之间的高带宽互连。使用NVLink毗邻两张NVIDIA GPU,即可弹性调整影象体与效能,知足专业视觉运算最高事情负载的需求。
自2014年最先,英伟达在其GPU中引入了NVLink互联手艺。
彼时,为带宽不足而发愁的英伟达,与那时坐拥更高带宽POWER CPU的IBM一拍而合,互助开发了*代NVLink。
回首NVLink手艺的生长历程:
2014年,NVLink 1.0宣布并在P100 GPU芯片之间实现,两个GPU之间有四个NVLink,每个链路由八个通道组成,每个通道的速率为20Gb/s,系统整体双向带宽为160GB/s,是PCIe3 x16的五倍,这使得数据在CPU内存与GPU显存之间的移动速率获得了大幅提升,从而让GPU加速的应用能够大幅提升运行速率。
随同着P100、V100等盘算卡的推出,NVLink迎来了自己的高速生长。
2017年,英伟达推出了第二代NVLink,两个V100 GPU芯片之间通过六个NVLink 2.0毗邻,每个链路也是由八个通道组成,每个通道的速率提升至25Gb/s,从而实现300GB/s的双向系统带宽,险些是NVLink1.0的两倍。
同时,为了实现八个GPU之间的完全互连,解决GPU之间通讯不平衡问题,英伟达还引入了NVSwitch手艺。
NVSwitch是英伟达在2018年宣布的一项手艺,旨在解决单服务器中多个GPU之间的全毗邻问题。NVSwitch允许单个服务器节点中多达16个GPU实现全互联,这意味着每个GPU都可以与其他GPU直接通讯,无需通过CPU或其他中介。
NVSwitch1.0有18个端口,每个端口的带宽为50GB/s,总带宽为900GB/s。每个NVSwitch保留两个用于毗邻CPU的端口。通过使用6个NVSwitch,可以在8个GPU V100芯片之间确立一个全毗邻的网络。
2020年,推出NVLink 3.0手艺。它通过12个NVLink毗邻毗邻两个GPU A100芯片,每个链路由四个通道组成。每个通道以50Gb/s的速率运行,从而发生600GB/s的双向系统带宽,是NVLink2.0的两倍。随着NVLink数目的增添,NVSwitch上的端口数目也增添到36个,每个端口的运行速率为50GB/s。
2022年,NVLink手艺升级到第四代,允许两个GPU H100芯片通过18条NVLink链路互连。每个链路由2个通道组成,每个通道支持100Gb/s(PAM4)的速率,从而使双向总带宽增添到900GB/s。NVSwitch也升级到了第三代,每个NVSwitch支持64个端口,每个端口的运行速率为 50GB/s。
值得一提的是,在第四代NVLink宣布时,英伟达正式将其称为NVLink-C2C ,此时NVLink已经升级为板级互连手艺,它能够在单个封装中将两个处置器毗邻成一块超级芯片。
2024年,随着英伟达全新Blackwell架构的宣布,NVLink 5.0也随之而来。
NVLink 5.0以100GB/s的速率在处置器之间移动数据。每个GPU有18个NVLink毗邻,Blackwell GPU将为其他GPU或Hopper CPU提供每秒1.8TB的总带宽,这是NVLink 4.0带宽的两倍,是行业尺度PCIe Gen5总线带宽的14倍。NVSwitch也升级到了第四代,每个NVSwitch支持144个NVLink 端口,无壅闭交流容量为14.4TB/s。
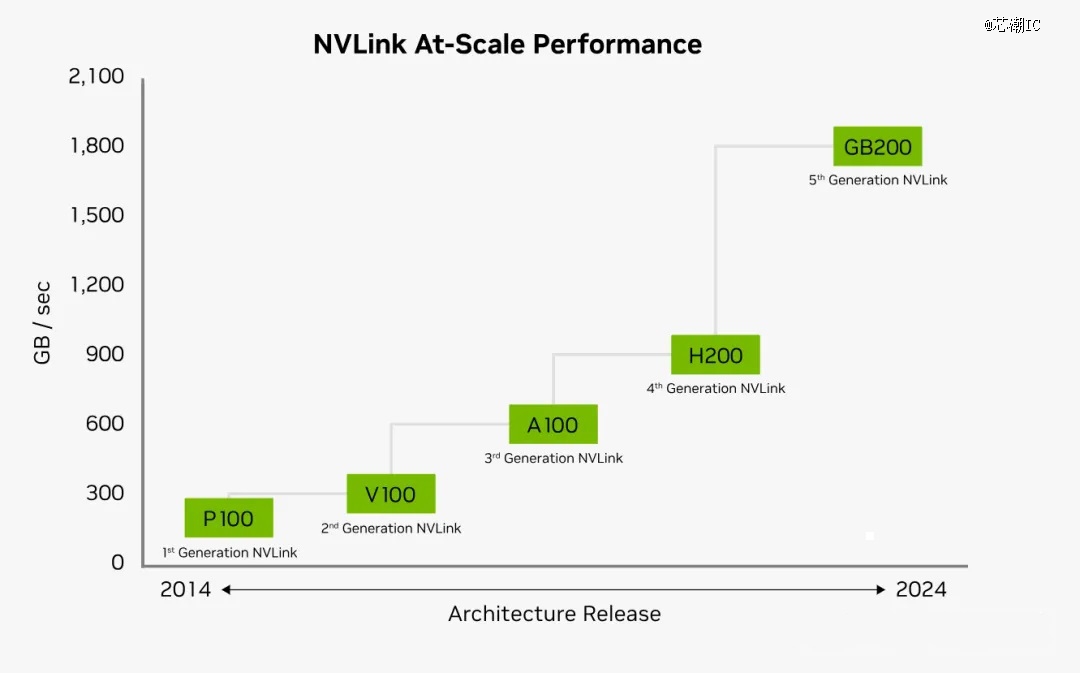
图源:英伟达
从上图可以看到,每一代NVLink的更新,其每个GPU的互联带宽都是在不停的提升,其中NVLink之间能够互联的GPU数,也从*代的4路到第四代/第五代的18路。每个NVLink链路的速率也由*代的20Gb/s提升至现在的1800Gb/s。
此外,只管拥有极高的带宽,NVLink却在每比特数据的传输上比PCIe节能得多。
NVLink和NVSwitch这两项手艺的引入,为GPU集群和深度学习系统等应用场景带来了更高的通讯带宽和更低的延迟,从而提升了系统的整体性能和效率。
随着下一代AI算法等先进盘算的需求不停增进,可以期待NVLink的功效进一步增强。无论是带宽的增添照样促进GPU之间更好互助的新功效,NVLink或厥后继者无疑仍将是知足未来盘算需求的焦点。
可见,当竞争对手还在追赶英伟达GPU性能时,英伟达已经在发力整个数据中央的构架层创新,通过提供更快的芯片互联,更强的算力调剂能力,将GPU打包成综合性能无人能敌的数据工厂,交付给全天下。
AMD加码Infinity Fabric
AMD也推出了与英伟达NVLink相似的Infinity Fabric手艺。
长剧热度回归,商业价值仍碾压短剧?
Infinity Fabric由两部门组成:数据布线(Data Fabric)和控制布线(Control Fabric),数据布线用于处置器内部和处置器之间的数据传输;控制布线则认真处置器的功耗、时钟和平安性等方面的治理,该手艺支持芯片间、芯片对芯片以及节点对节点的数据传输。
Infinity Fabric的主要特点包罗:
高效率:Infinity Fabric设计用于提供高效率的数据传输,支持多个装备之间的高速通讯;
模块化:Infinity Fabric支持AMD的Chiplet架构,允许差异功效的芯片模块通过高速互连举行组合;
内存共享:Infinity Fabric支持CPU和GPU之间的内存共享,有助于提高异构盘算效率;
扩展性:Infinity Fabric的设计允许它随着手艺提高和需求增进而扩展。
Infinity Fabric是AMD在其“Zen微架构”中引入的一个要害特征,旨在提高整系一切性能,稀奇是在多焦点处置器和数据中央环境中。

图源:AMD
据悉,AMD最新的AI加速器Instinct MI300X平台,就是通过第四代Infinity Fabric链路将8个完全毗邻的MI300X GPU OAM模块集成到行业尺度OCP设计中,为低延迟AI处置提供高达1.5TB HBM3容量。第四代Infinity Fabric支持每通道高达32Gbps,每链路发生128GB/s的双向带宽。
差异于英伟达NVLink仅限于内部使用,AMD已经最先向互助同伴开放其Infinity Fabric生态系统,完善生态结构。
芯片巨头组团,向英伟达NVLink开战
只管GPU互联手艺看上去种类多样,但主要手艺蹊径照样牢牢掌握在英伟达手中,业界一直期待有某种“超级”竞争对手同盟来填补非Nvidia互联手艺或集群的空缺。
而这也正是UALink推出的主要缘故原由,掀起对标英伟达NVLink的波涛。
文章开头提到,AMD、博通、思科、Google、惠普、英特尔、Meta和微软在内的八家公司宣告,为人工智能数据中央的网络制订了新的互联手艺UALink(Ultra Accelerator Link)。通过为AI加速器之间的通讯确立一个开放尺度,以挑战英伟达在AI加速器一家独大的职位。
据新闻披露,UALink提议的*个尺度版本UALink 1.0,将毗邻多达1024个GPU AI加速器,组成一个盘算“集群”,配合完成大规模盘算义务。
凭证UALink推广组的说法,基于包罗AMD的Infinity Fabric在内的“开放尺度”,UALink 1.0将允许AI加速器所附带的内存之间的直接加载和存储,而且与现有互连规范相比,总体上将提高速率,同时降低数据传输延迟。
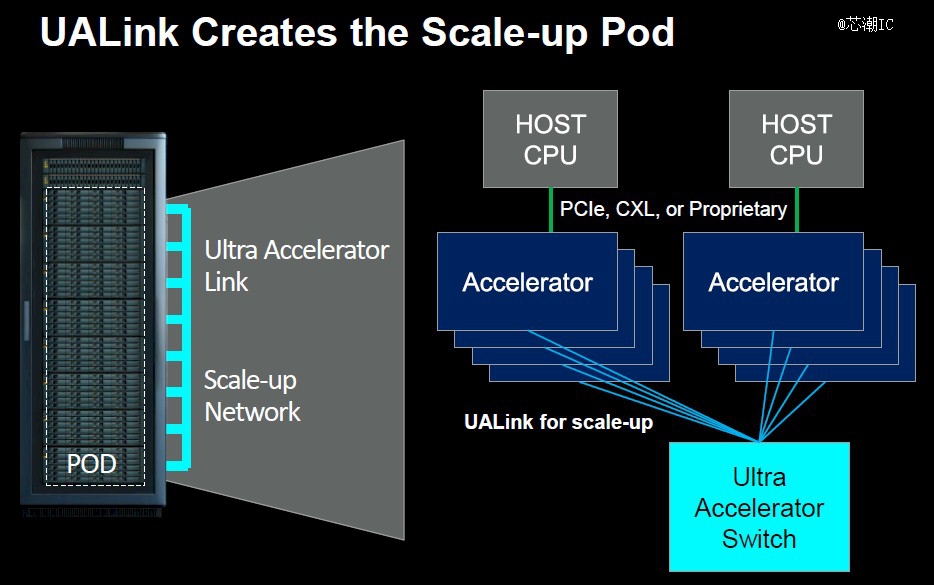
图源:nextplatform
据悉,UALink将在第三季度确立一个UALink同盟,界说AI盘算舱中加速器和交流机之间扩展通讯的高速、低延迟互连,以监视UALink规范未来的生长。UALink 1.0将在同期向加入同盟的公司提供,而具有更高带宽的更新规范UALink 1.1,设计在2024年第四序度推出。这些规范将支持多种传输,包罗PCI-Express和以太网。
UALink同盟旨在确立一个开放的行业尺度,允许多家公司为整个生态系统增添价值,从而阻止手艺垄断。
该手艺的潜在优势在于让业内所有人都有时机与英伟达保持同步,其不仅适用于大型企业,也为行业中每小我私人打开了一扇门,让他们不仅在规模上,而且在创新方面都能跟上英伟达的措施。
多机互联:
InfiniBand与以太网络并存
03
此外,在漫衍式系统中,凭证毗邻层级的差异可以分为单卡、多卡、多机互联,在大规模盘算中,单机多卡场景下多使用GPU Diect、NVLink等高带宽通讯网络手艺,漫衍式场景下的多机之间的毗邻(即服务器互联)通常接纳RDMA网络。
随着大数据剖析、AI盘算等应用对算力需求伟大,上面提到的单机形态已经逐渐不能知足用户需求,多机多卡的盘算成为常态,多机间的通讯是影响漫衍式训练的一个主要指标。
当前业界常提到的多机之间GPU卡的通讯手艺,主要有RDMA、GPU Direct RDMA和InfiniBand等手艺。
RDMA是一种绕过远程主机而直接接见其内存中数据的手艺,解决网络传输中数据处置延迟而发生的一种远端内存直接接见手艺。
简朴明白,RDMA就像一个去掉中央商的手艺,让数据能够快速获取。不再在操作系统、CPU等环节虚耗时间。
现在RDMA有三种差其余手艺实现方式:Infiniband、RoCE、iWARP,后两者是基于以太网的手艺。
耐久以来,以太网一直是盘算机网络的主力,例如英特尔的Gaudi系列AI处置器在芯片上集成了几十个100Gb以太网毗邻;相比之下,英伟达通过收购Mellanox独占了高性能InfiniBand互连市场。
InfiniBand是一种开放尺度的网络互连手艺,具有高带宽、低延迟、高可靠性的特点,在英伟达的AI工厂和超级电脑中饰演着至关主要的角色。
InfiniBand在人工智能等数据麋集型义务中通常优于以太网。据Dell'Oro估量,约90%的AI部署都是使用的InfiniBand,而不是以太网。这些部署将英伟达的网络收入推至每年100亿美元。
英特尔,押注以太网
英特尔的Gaudi AI芯片则一直沿用传统的以太网互联手艺。
据领会,Gaudi 2每个芯片使用了24个100Gb以太网链路;Gaudi 3将这些链路的带宽增添了一倍,使用了24个200Gbps以太网RDMA NIC,使芯片的外部以太网I/O总带宽到达8.4TB/秒。
前不久,英特尔还宣布正在开发一款用于超以太网同盟(UEC)兼容网络的AI NIC ASIC以及一款AI NIC小芯片,这些创新的AI高速互联手艺将用于其未来的XPU和Gaudi 3处置器。这些创新旨在刷新可大规模纵向和横向扩展的AI高速互联手艺。
超以太网同盟(UCE),是一个由英特尔、AMD、HPE、Arista、Broadcom、思科、Meta和微软为打破英伟达垄断而配合确立的组织。UCE以为,通过调整以太网的架构,可以让以下一代高速太网的性能像InfiniBand网络一样好,并更具成本与开放性优势,从而让更多的企业加入进来。
一直以来,英特尔都希望通过接纳纯以太网交流机来赢得那些不想投资InfiniBand等专有互连手艺的客户。
虽然InfiniBand在许多情形下显示都不错,但它也有瑕玷,好比只能在特定局限内使用(例如InfiniBand适合那些运行少量异常大的事情负载(例如GPT3或数字孪生)的用户,但在加倍动态的超大规模和云环境中,以太网通常是*),而且成本也不低,将整个网络升级到InfiniBand需要大量投资。相比之下,以太网由于兼容性强,成本适中,以及能够胜任大多数事情负载,以是在网络手艺领域里一直很受迎接,确立了一个重大的“以太网生态”。
AMD也示意将重点支持以太网,稀奇是超以太网同盟。虽然Infinity Fabric提供了GPU之间的一致互连,但AMD正在推广以太网作为其*的GPU到GPU网络。
综合来说,高性能远距离传输的战场里,现在仅剩InfiniBand和下一代高速以太网两大阵营,双方各有优劣势。
据Dell'Oro预计,在可预见的未来InfiniBand将保持在AI交流领域的*职位,但在云和超大规模数据中央的推动下,以太网将取得大幅增进,预计到2027年将占有约20%的市场份额。
互联手艺未来创新趋势
04
不能否认,上述这些互联手艺都已是现在*的选择。但能够预见到是,随着未来盘算数据的爆炸式增进、神经网络庞大性不停增添,以及AI手艺的加速演进,对更高带宽的需求还在继续增进。
当前这些互联手艺将不能阻止的存在性能瓶颈。
例如英伟达的NVLink虽然速率快,但功耗也相当高;AMD的Infinity Fabric适合于芯片内部毗邻,对于芯片之间的互联效率并不理想等。
对此,光互联依附高带宽、低功耗等优势,险些成为未来AI互联手艺公认的生长偏向。
在光互联之路上,谷歌、博通、Marvell、思科以及Celestial AI、Ayar Labs、Lightmatter、Coherent、曦智科技等新老厂商都在不停发力,相继取得了一系列功效。
在众多厂商的介入下,互联手艺未来将会迎来快速生长。尤其是围绕光电共封装和硅光子中继层手艺的光互连,正在成为AI领域的热门赛道。
结语
05
大模子时代,算力就是生产力。
大模子的背后意味着伟大的盘算资源,模子巨细和训练数据巨细成为决议模子能力的要害因素。当前,市场的主力玩家们行使数万个GPU构建大型人工智能集群,以训练LLM。
在此趋势下,漫衍式通讯手艺正以亘古未有的速率推动着人工智能的提高。
从PCIe到NVLink、Infinity Fabric再到InfiniBand、以太网和UALink,这些手艺通过高带宽、低延迟的数据传输,实现了GPU或AI服务器之间的高速互联,在提升深度学习模子的训练效率和盘算性能方面施展了至关主要的作用。
在AI手艺的飞速生长中,互联手艺作为AI时代的桥梁,也正在履历亘古未有的创新与变化。
————正大国际期货金融有限公司