
来源:正大期货 2024-06-26 08:58
克日,AI芯片初创公司Etched宣布,已筹集 1.2 亿美元,向 Nvidia 提议 AI 芯片设计挑战。
Etched 正在设计一款名为 Sohu 的新芯片,用于处置 AI 处置的一个要害部门:Transformation。该公司示意,通过将 Transformer 架构刻录到芯片中,它正在打造天下上最壮大的 Transformer 推理服务器。Etched 示意,这是有史以来最快的 Transformer 芯片。
Primary Venture Partners 和 Positive Sum Ventures 领投了此轮融资,并获得了 Hummingbird、Fundomo、Fontinalis、Lightscape、Earthshot、Two Sigma Ventures(战略)和 Skybox Data Centers(战略)等机构投资者的支持。
值得一提的是,该公司的天使投资人包罗 Peter Thiel、Stanley Druckenmiller、 David Siegel、Balaji Srinivasan、Amjad Masad、Kyle Vogt、Kevin Hartz、Jason Warner、Thomas Dohmke、Bryan Johnson、Mike Novogratz、Immad Akhund、Jawed Karim 和 Charlie Cheeve。
泰尔奖学金主任亚历克斯·汉迪 (Alex Handy) 在一份声明中示意:“投资 Etched 是对人工智能价值的战略押注。他们的芯片解决了竞争对手不敢解决的可扩展性问题,挑战了偕行普遍存在的阻滞不前征象。Etched 的首创人体现了我们支持的非传统人才——从哈佛辍学,进军半导体行业。他们支出了艰辛的起劲,以便硅谷的其他人可以继续放心地编程,而不必忧郁他们正在研究的任何底层手艺。”

Etched首创人:Robert Wachen、Gavin Uberti、Chris Zhu
Transformer一统江湖, GPU撞墙
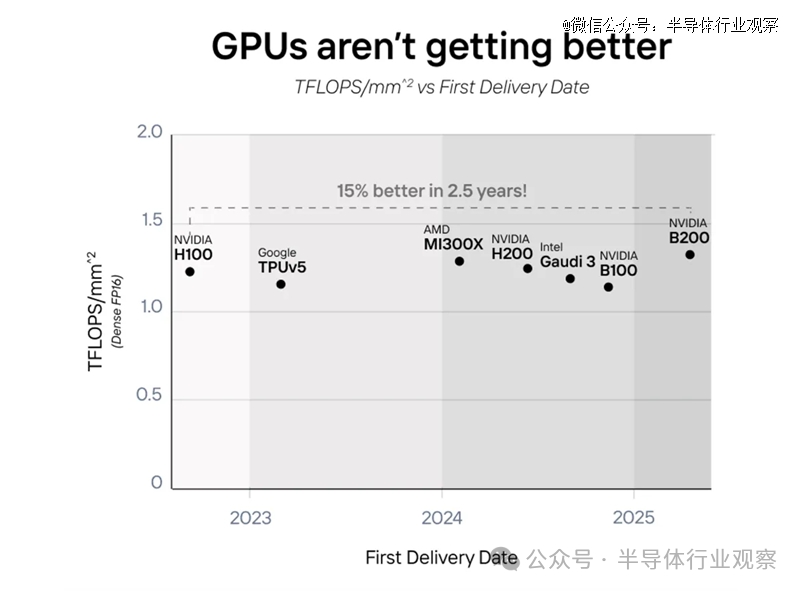
正如人人所所看到的,已往解决AI问题,都是考GPU。不外Etched在博客中示意,圣克拉拉的隐秘是,GPU 并没有变得更好,而是变得更大了。四年来,芯片单元面积的盘算能力 (TFLOPS) 险些保持稳固。
他们示意,NVIDIA 的 B200、AMD 的 MI300、英特尔的 Gaudi 3 和亚马逊的 Trainium2 都将两块芯片算作一张卡,以实现“双倍”性能。从 2022 年到 2025 年,AI 芯片并没有真正变得更好,而是变得更大了。2022 年到 2025 年,所有 GPU 性能提升都使用了这个技巧,但Etched 除外。
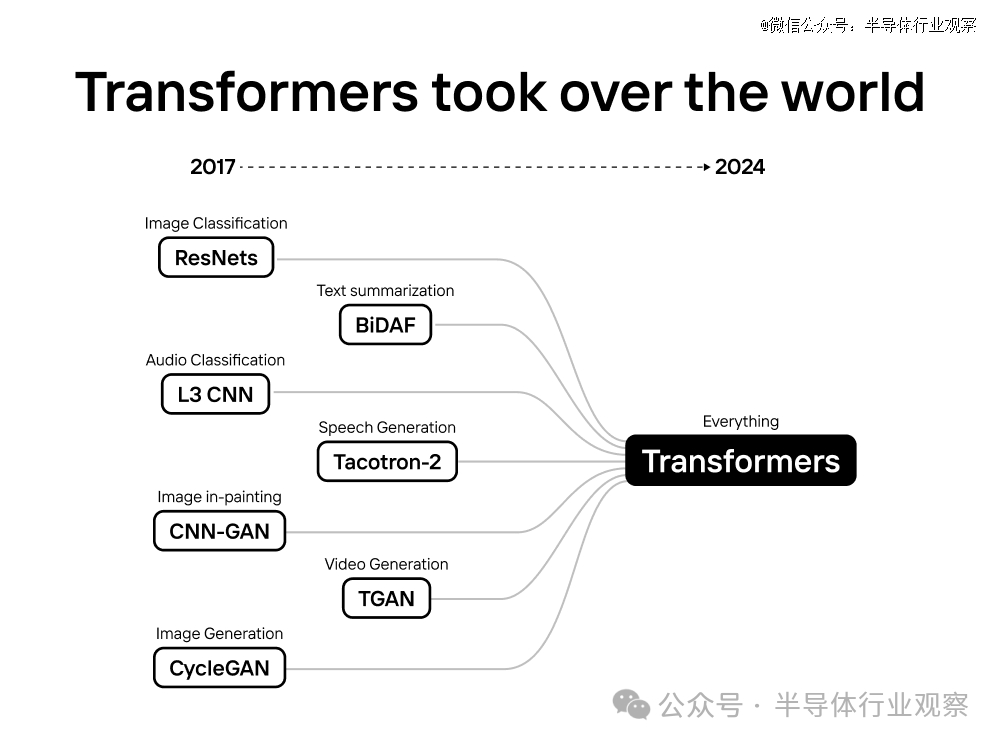
在 transformer 统治天下之前,许多公司都构建了天真的 AI 芯片和 GPU 来处置数百种差其余架构。以下枚举一些:
NVIDIA的GPUs、Google的TPUs、Amazon的Trainium、AMD的加速器、Graphcore的IPUs、SambaNova SN Series、Cerebras的CS-2、Groq的GroqNode、Tenstorrent的Grayskull、D-Matrix的Corsair、Cambricon的Siyuan和Intel的Gaudi.
从来没有人制造过专门针对算法的 AI 芯片 (ASIC)。芯片项目的成本为 5000 万至 1 亿美元,需要数年时间才气投入生产。我们刚最先时,没有市场。
突然间,情形发生了转变:
亘古未有的需求:在 ChatGPT 之前,Transformer 推理的市场约为 5000 万美元,现在则到达数十亿美元。所有大型科技公司都使用 Transformer 模子(OpenAI、谷歌、亚马逊、微软、Facebook 等)。
架构上的融合:AI 模子已往转变很大。但自 GPT-2 以来,*进的模子架构险些保持稳固!OpenAI 的 GPT 系列、谷歌的 PaLM、Facebook 的 LLaMa,甚至 Tesla FSD 都是 Transformer。
当模子的训练成本跨越 10 亿美元,推理成本跨越 100 亿美元时,专用芯片是不能阻止的。在这个规模下,1% 的改善将证实 5000 万至 1 亿美元的定制芯片项目是合理的。
事实上,ASIC 的速率比 GPU 快几个数目级。当比特币矿机于 2014 年进入市场时,抛弃 GPU 比使用它们来挖掘比特币更廉价。
由于涉及数十亿美元的资金,人工智能也将发生同样的情形。
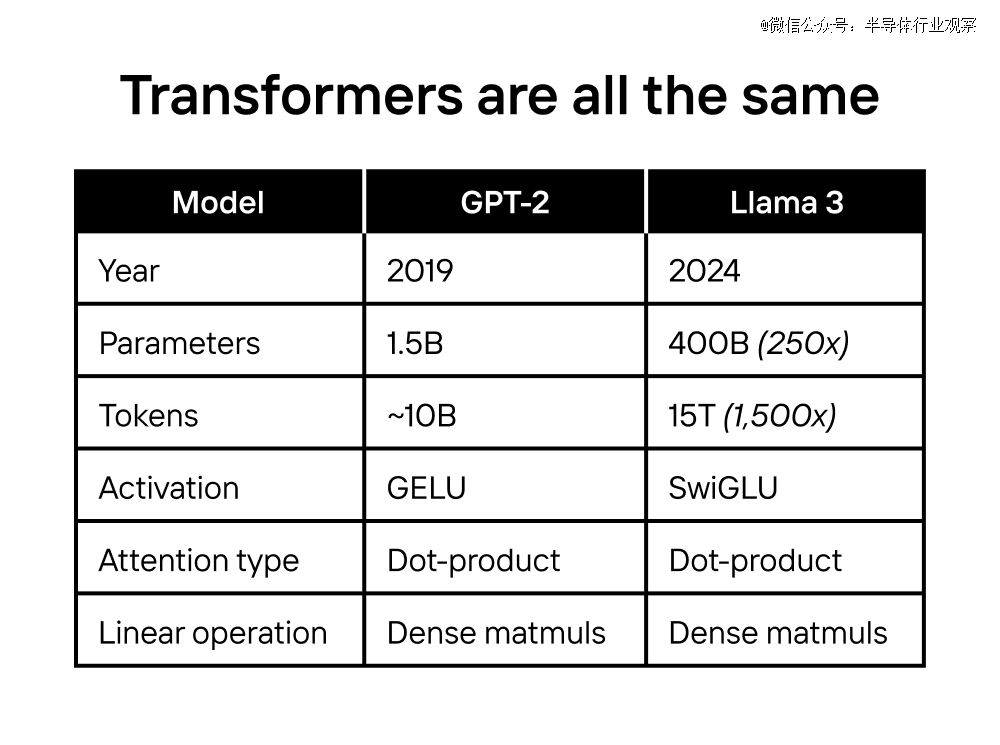
Transformer 惊人地相似:诸如 SwiGLU 激活和 RoPE 编码之类的调整随处可见:LLM、嵌入模子、图像修复和视频天生。
虽然 GPT-2 和 Llama-3 是相隔五年的*进的 (SoTA) 模子,但它们的架构险些相同。*的主要区别是规模。
Etched信托硬件彩票(hardware lottery):获胜的模子是那些可以在硬件上运行速率最快、成本*的模子。Transformer 功效壮大、适用且利润丰盛,足以在替换品泛起之前主宰每个主要的 AI 盘算市场:
Transformer 为每一种大型 AI 产物提供动力:从署理到搜索再到谈天。AI 实验室已破费数亿美元举行研发,以优化 GPU 以顺应 Transformer。当前和下一代*进的模子都是 Transformer。
随着模子在未来几年从 10 亿美元扩展到 100 亿美元再到 1000 亿美元的训练运行,测试新架构的风险飙升。与其重新测试缩放定律和性能,不如花时间在 Transformer 之上构立功效,例如多token展望。
当今的软件客栈针对 Transformer 举行了优化。每个盛行的库(TensorRT-LLM、vLLM、Huggingface TGI 等)都有用于在 GPU 上运行 Transformer 模子的特殊内核。许多基于 transformer 构建的功效在替换方案中都不容易获得支持(例如推测解码、树搜索)。
未来的硬件客栈将针对 transformer 举行优化。NVIDIA 的 GB200 稀奇支持 transformer(TransformerEngine)。像 Sohu 这样的 ASIC 进入市场标志着不归路。Transformer 杀手在 GPU 上的运行速率需要比 transformer 在 Sohu 上运行的速率更快。若是发生这种情形,我们也会为此构建一个 ASIC!
两个哈佛辍学生确立芯片公司
随着天生式人工智能触及越来越多的行业,生产运行这些模子的芯片的公司受益匪浅。尤其是英伟达,其影响力伟大,占有了人工智能芯片市场约70% 至 95% 的份额。从Meta到微软,云提供商都在英伟达 GPU 上投入了数十亿美元,忧郁在天生式人工智能竞赛中落伍。
因此,天生式人工智能供应商对现状不满也是可以明白的。他们的乐成很洪水平上取决于主流芯片制造商的意愿。因此,他们与时机主义风险投资公司一起,正在寻找有前途的新兴企业来挑战人工智能芯片巨头。
Etched是众多争取一席之地的另类芯片公司之一,但它也是最有趣的公司之一。Etched 确立仅两年,由两位哈佛辍学生 Gavin Uberti(前OctoML和前Xnor.ai员工)和 Chris Zhu 确立,他们与 Robert Wachen 和前赛普拉斯半导体公司首席手艺官 Mark Ross 一起,试图缔造一种可以做一件事的芯片:运行 AI 模子。
这并不罕有,许多初创公司和科技巨头都在开发专门运行人工智能模子的芯片,也称为推理芯片。Meta 有MTIA,亚马逊有Graviton和Inferentia等等。但 Etched 的芯片的怪异之处在于它们只运行一种类型的模子:Transformers。
Transformer 由谷歌研究团队于 2017 年提出,现在已成为主流的天生式 AI 模子架构。
Transformer 是 OpenAI 视频天生模子Sora的基础。它们是 Anthropic 的Claude和谷歌的Gemini等文本天生模子的焦点。它们还为最新版本的 Stable Diffusion等艺术天生器提供动力。
在一篇新博客文章中,Etched首创人示意,该公司在 2022 年 6 月对人工智能举行了*的押注,那时它押注一种新的人工智能模子将接受天下:Transformer。
在Etched看来,五年内,AI 模子在大多数尺度化测试中都比人类更伶俐。
怎么会这样?由于 Meta 训练 Llama 400B(2024 SoTA,比大多数人类更伶俐)所用的盘算量是 OpenAI 在 GPT-2(2019 SoTA)上所用的 50,000 倍。
通过为 AI 模子提供更多盘算和更好的数据,它们会变得更伶俐。规模是几十年来*连续有用的窍门,每家大型 AI 公司(谷歌、OpenAI / 微软、Anthropic / 亚马逊等)都将在未来几年投入跨越 1000 亿美元来保持规模。我们正处于有史以来*的基础设施建设中。
但再扩大 1,000 倍将异常昂贵。下一代数据中央的成本将跨越一个小国的 GDP。根据现在的速率,我们的硬件、电网和钱包都跟不上。
我们并不忧郁数据耗尽。无论是通过合成数据、注释管道照样新的 AI 符号数据源,我们都以为数据问题现实上是推理盘算问题。Mark Zuckerberg4、Dario Amodei5 和 Demis Hassabis6似乎赞成这一看法。
“2022 年,我们赌博Transformer将统治天下,”Etched 首席执行官 Uberti 在接受 TechCrunch 采访时示意。“在人工智能的生长中,我们已经到达了一个节点,性能优于通用 GPU 的专用芯片是不能阻止的——全天下的手艺决议者都知道这一点。”
那时,AI 模子种类繁多,有用于自动驾驶汽车的 CNN、用于语言的 RNN 以及用于天生图像和视频的 U-Net。然而,Transformer(ChatGPT 中的“T”)是*个可以扩展的模子。
首席执行官 Gavin Uberti 在博文中示意:“我们赌博,若是智能随着盘算不停扩展,几年之内,公司将在 AI 模子上投入数十亿美元,所有模子都在专用芯片上运行。”“我们花了两年时间打造了天下上*款Transformer专用芯片 (ASIC) Sohu。我们将Transformer架构刻录到我们的芯片中,我们无法运行传统的 AI 模子:为您的 Instagram 提要提供支持的 DLRM、来自生物实验室的卵白质折叠模子或数据科学中的线性回归。”
一颗名为“sohu”的4nm芯片
Etched 的芯片名为 Sohu,是一款 ASIC(专用集成电路)。Uberti 声称,Sohu 接纳台积电的 4nm 工艺制造,可以提供比 GPU 和其他通用 AI 芯片更好的推理性能,同时消耗更少的能源。
Uberti 示意:“在运行文本、图像和视频转换器时,Sohu 的速率甚至比 Nvidia 的下一代 Blackwell GB200 GPU 快一个数目级,而且成本更低。一台 Sohu 服务器可取代 160 个 H100 GPU。……对于需要专用芯片的企业*来说,Sohu 将是一个更经济、更高效、更环保的选择。”
Uberti 弥补道:“我们也无法运行 CNN、RNN 或 LSTM。但对于 transformer 来说,Sohu 是有史以来最快的芯片。它甚至没有竞争对手。Sohu 的速率甚至比 Nvidia 的下一代 Blackwell (GB200) GPU 快一个数目级,而且更廉价,适用于文本、音频、图像和视频 transformer。”
雷军投资的渔业平台,要IPO了
Uberti示意,自他们确立以来,每个主要的 AI 模子(ChatGPT、Sora、Gemini、Stable Diffusion 3、Tesla FSD 等)都酿成了 transformer。不外,若是 transformer 突然被 SSM、monarch 夹杂器或任何其他类型的架构取代,Etched 的芯片将毫无用处。
“但若是我们是对的,Sohu将改变天下,”Uber信心满满地说。
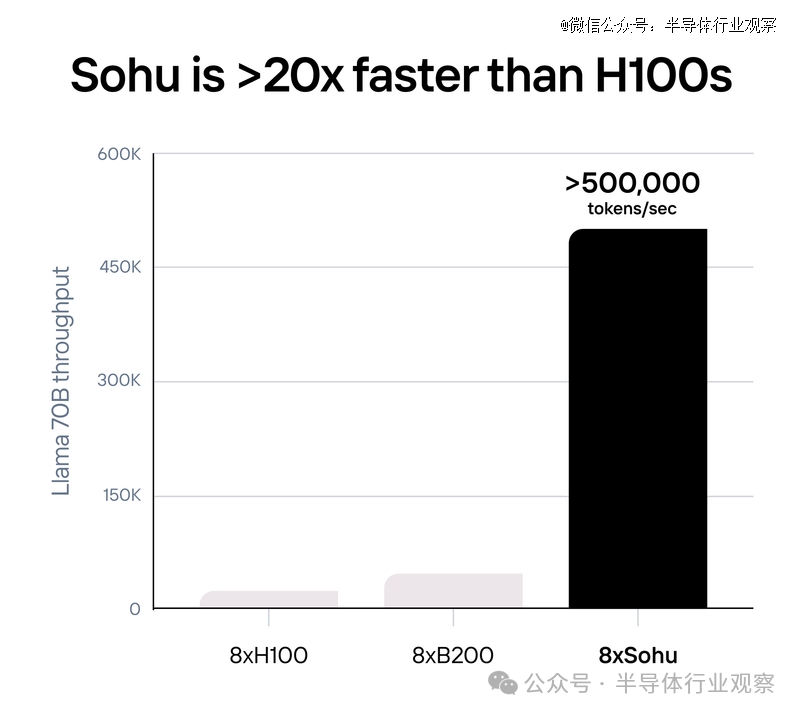
通过专业化,Sohu获得了亘古未有的性能。一台 8xSohu 服务器每秒可以处置跨越 500,000 个 Llama 70B token。
据先容,Sohu 仅支持转换器推理,无论是 Llama 照样 Stable Diffusion 3。Sohu 支持当今的所有模子(Google、Meta、Microsoft、OpenAI、Anthropic 等),而且可以处置对未来模子的调整。
由于 Sohu 只能运行一种算法,因此可以删除绝大多数控制流逻辑,从而允许它拥有更多的数学块。因此,Sohu 拥有跨越 90% 的 FLOPS 行使率(而使用 TRT-LLM 的 GPU7 上约为 30%)。
强悍性能,若何做到?
Sohu是若何实现这一切的?有几种方式,但最显著(也是最直观)的方式是简化推理硬件和软件管道。由于Sohu不运行非transformer模子,因此 Etched 团队可以作废与transformer无关的硬件组件,并削减传统上用于部署和运行非transformer的软件开销。
Etched在一篇博客文章中示意,NVIDIA H200 拥有 989 TFLOPS 没有希罕性的 FP16/BF16 盘算能力。这是*进的(甚至比谷歌的新 Trillium 芯片还要好),而 2025 年推出的 GB200 的盘算能力仅增添了 25%(每个die 1250 TFLOPS)。
由于 GPU 的绝大部门区域都用于可编程性,因此专注于transformer可以让您举行更多的盘算。您可以从*原理向自己证实这一点:
构建单个 FP16/BF16/FP8 乘加电路需要 10,000 个晶体管,这是所有矩阵数学的基石。H100 SXM 有 528 个张量焦点,每个都有 4 × 8 × 16 FMA 电路。乘法告诉我们 H100 有 27 亿个专用于张量焦点的晶体管。
但 H100 有 800 亿个晶体管12!这意味着 H100 GPU 上只有 3.3% 的晶体管用于矩阵乘法!
这是 NVIDIA 和其他天真 AI 芯片经由深图远虑的设计决议。若是您想支持种种模子(CNN、LSTM、SSM 等),没有比这更好的了。
通过仅运行 Transformer,Etched可以在芯片上安装更多的 FLOPS,而无需降低精度或希罕性。
有看法以为,推理的瓶颈是内存带宽,而不是盘算?事实上,对于像 Llama-3 这样的现代模子来说,谜底是显而易见的!
让我们使用 NVIDIA 和 AMD 的尺度基准 :2048 个输入tokens和 128 个输出tokens。大多数 AI 产物的prompts 比completions时间长得多(纵然是新的 Claude 谈天在系统提醒中也有 1,000 多个tokens)。
在 GPU 和Sohu上,推理是分批(batches)运行的。每个批次都市加载所有模子权重一次,并在批次中的每个符号中重复使用它们。通常,LLM 输入是盘算麋集型的,而 LLM 输出是内存麋集型的。当我们将输入和输出token与延续批处置相连系时,事情负载会变得异常受盘算麋集型。
下面是 LLM 延续批处置的一个例子。在这里,我们正在运行具有四个输入符号和四个输出符号的序列;每种颜色都是差其余序列。
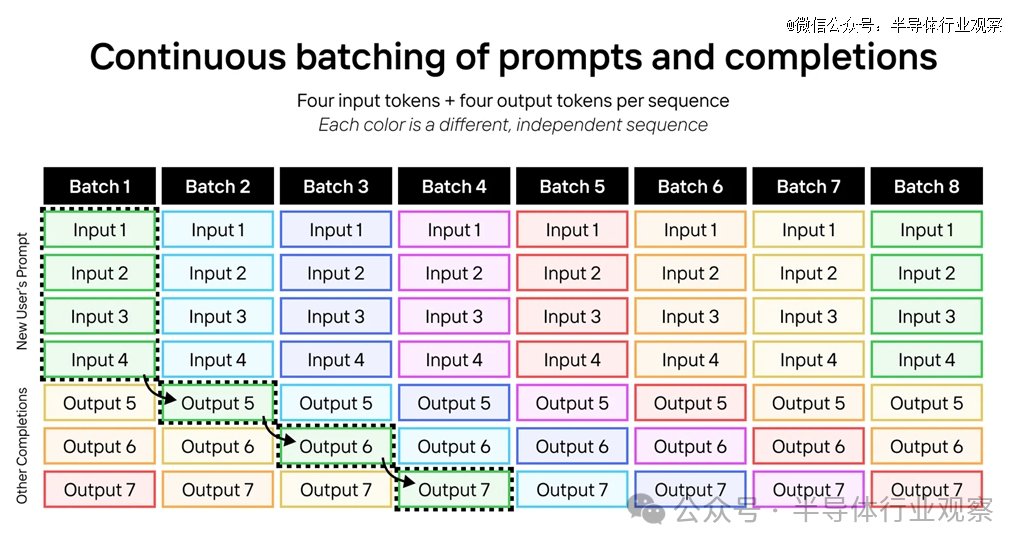
我们可以扩展相同的技巧来运行具有 2048 个输入token和 128 个输出token的 Llama-3-70B。让每个批次包罗一个序列的 2048 个输入token和 127 个差异序列的 127 个输出tome。
若是我们这样做,每个批次将需要约莫 (2048 127) × 70B 参数 × 每个参数 2 字节 = 304 TFLOP,而只需加载 70B 参数 × 每个参数 2 字节 = 140 GB 的模子权重和约莫 127 × 64 × 8 × 128 × (2048 127) × 2 × 2 = 72GB 的 KV 缓存权重。这比内存带宽要多得多:H200 需要 6.8 PFLOPS 的盘算才气*限度地行使其内存带宽。这是行使率为 100% 的情形 - 若是行使率为 30%,则需要 3 倍以上的内存。
由于Sohu拥有云云多的盘算能力和极高的行使率,我们可以运行伟大的吞吐量,而不会泛起内存带宽瓶颈。
而在现实天下中,批次要大得多,输入长度各不相同,请求以泊松漫衍(Poisson distribution)到达。这种手艺在这些情形下效果更好,但我们在此示例中使用 2048/128 基准,由于 NVIDIA 和 AMD 使用它。
众所周知,在 GPU 和 TPU 上,软件是一场噩梦。处置随便 CUDA 和 PyTorch 代码需要异常庞大的编译器。第三方 AI 芯片(AMD、Intel、AWS 等)在软件上破费了数十亿美元,但收效甚微。
但由于Sohu只运行 transformer,我们只需要为 transformer 编写软件!
大多数运行开源或内部模子的公司都使用特定于 transformer 的推理库,如 TensorRT-LLM、vLLM 或 HuggingFace 的 TGI。这些框架异常僵化 - 虽然你可以调整模子超参数,但现实上不支持更改底层模子代码。但这没关系 - 由于所有 transformer 模子都异常相似(甚至是文本/图像/视频模子),调整超参数就是你真正需要的。
虽然这支持 95% 的 AI 公司,但*的 AI 实验室接纳定制。他们有工程师团队手动调整 GPU 内核以挤出稍微更多的行使率,逆向工程哪些寄存器对每个张量焦点的延迟*。
有了 Etched,您无需再举行逆向工程 - 由于Etched的软件(从驱动程序到内核再到服务客栈)都将是开源的。若是您想实现自界说转换层,您的内核向导可以自由地这样做。
Etched将成为全球*
Uberti说,每一个大型同质盘算市场最终都市以专用芯片竣事:网络、比特币挖掘、高频生意算法都被硬编码到硅片中。
这些芯片的速率比 GPU 快几个数目级。没有一家公司使用 GPU 来挖掘比特币——他们基本无法与专业的比特币矿工竞争。人工智能也会发生这种情形。Uberti 说,由于涉及数万亿美元,专用是不能阻止的。
“我们以为,绝大部门支出(和价值)将用于具有跨越 10 万亿个参数的模子。由于延续批处置的经济性,这些模子将在数十个 MegaClusters 之一的云端运行,”Uberti 说。“这种趋势将反映芯片工厂:已往有数百个廉价的低分辨率工厂,而现在,高分辨率工厂的建设成本约为 200 亿至 400 亿美元。天下上只有少数几个 MegaFab,它们都使用异常相似的底层架构(EUV、858 平方毫米掩模版、300 毫米晶圆等)。”
Etched 示意,Transformer 的转换成本异常高。纵然发现晰一种比 Transformer 更好的新架构,重写内核、重修推测解码等功效、构建新的专用硬件、重新测试缩放定律以及重新培训团队的阻力也是伟大的。Uberti 示意,这种情形十年内只会发生一两次,就像芯片领域发生的情形一样:光刻手艺、掩模版/晶圆尺寸和光刻胶因素的转变确实会继续发生,但转变速率异常缓慢。
“我们扩展 AI 模子的水平越高,我们就越会集中于模子架构。创新将发生在其他地方:推测解码、树搜索和新的采样算法,”Uberti 说。“在一个模子训练成本为 100 亿美元、芯片制造成本为 5000 万美元的天下里,专用芯片是不能阻止的。*制造它们的公司将获胜。”
Etched 断言,从来没有人制造过特定架构的 AI 芯片。纵然在去年,这也毫无意义。特定架构的芯片需要伟大的需求和对其持久力的坚定信心。
Uberti示意:“我们把赌注押在了Transformer 上,这两个要求都正在成为现实。”
该公司指出,市场需求已到达亘古未有的水平。Transformer 推理市场刚最先时不到 5000 万美元,而现在已跨越 50 亿美元。所有大型科技公司都在使用 Transformer 模子(OpenAI、谷歌、亚马逊、微软、Facebook 等)。
Uberti 示意,他们正在看到架构融合:已往,AI 模子会发生很大转变。但自 GPT-2 以来,*进的模子架构险些保持稳固。OpenAI 的 GPT 系列、Google 的 PaLM、Facebook 的 LLaMa,甚至 Tesla FSD 都是Transformer 。
Uberti 示意,公司正以极快的速率起劲将Sohu酿成现实。
Uberti 强调:“公司正朝着有史以来最快的速率推进,从架构到验证硅片,以用于 4nm 光罩巨细的芯片。”“我们直接与台积电互助,并从两家*供应商处双源采购 HBM3E。我们从 AI 和基础模子公司获得了数万万美元的预订,而且拥有足够的供应链能力来扩展。若是我们的赌注准确而且我们执行,Etched 将成为天下上*的公司之一。”
该公司重申,若是这一展望准确,Sohu将改变天下。
现在,AI 编码署理的盘算成本为 60 美元/小时,而且需要数小时才气完成义务,Gemini 需要 60 多秒才气回覆有关视频的问题16。编码署理的成本高于软件工程师,而且需要数小时才气完成义务。视频模子每秒天生一帧,甚至当 ChatGPT 注册用户到达 1000 万时(仅占全球的 0.15%),OpenAI 也耗尽了 GPU 容量。
我们无法解决这个问题 - 纵然我们继续以每两年 2.5 倍的速率制造更大的 GPU,也需要十年才气实现实时视频天生。
你设想一下,若是人工智能模子一夜之间速率提高 20 倍且成本降低,会发生什么?有了Sohu,实时视频、音频、署理和搜索终于成为可能。Uberti 示意,每款 AI 产物的单元经济效益将在一夜之间发生逆转。
据透露,该公司的早期客户已经预订了数万万美元的硬件。
在被问到 Etched 这样的小公司若何能击败 Nvidia。Etched 首席运营官团结首创人 Robert Wachen 在给 VentureBeat 的电子邮件中说:
“已往,AI 盘算市场是涣散的:人们使用差异类型的模子,例如 CNN、DLRM、LSTM、RNN 以及跨领域的数十种其他模子。每种架构的支出都在数万万到数亿美元之间,而这些事情负载的市场足够大,通用芯片 (GPU) 可以胜出,”Wachen 说道。
他指出,市场正在迅速整合为一种架构:Transformer。在人们破费数十亿美元购置变压器模子、定制芯片破费 5000 万至 1 亿美元的天下里,专用芯片是不能阻止的。
“我们的芯片在大多数事情负载下都无法击败 GPU——我们无法支持它们。然则,对于变压器推理(为每种主要的“天生式 AI”产物提供支持),我们将祛除市场。通过云云专业化,我们的芯片比下一代 Blackwell GPU 快一个数目级,”Wachen 说道。
参考链接
————正大国际期货金融有限公司